
티스토리 뷰

이번 포스팅에서는 Real MySQL, 시스템 성능 최적화, 데이터베이스를 지탱하는 기술, 데이터 전문가 지식 포털 을 활용하였습니다.
1. 왜 학습해야 할까?
대부분의 웹 애플리케이션은 DB에서 데이터를 조회하고 저장하는 작업이 주를 이루므로, 통상 서버 처리시간의 70% 이상이 SQL을 처리하는데 사용되곤 한다. (Datastore 비교)
성능과 관련된 이미 여러 글(부하란 무엇인가?, 테크세미나 후기)에서 언급했듯 성능 개선에 앞서 병목지점을 확인하는 것이 중요하다.
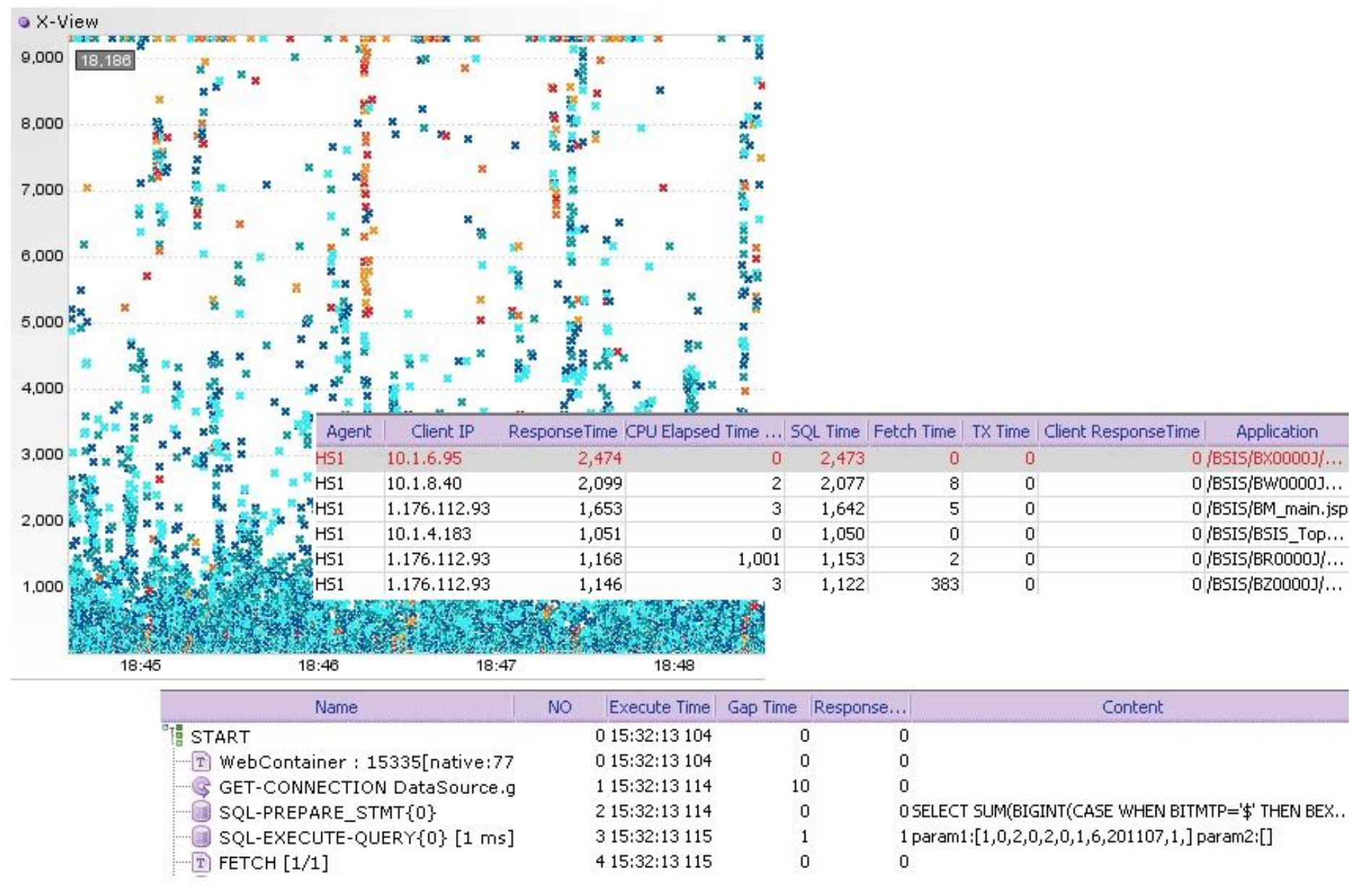
2. 어떤 단계로 학습할 것인가?
APM을 사용할 경우, 요청의 지연현상을 파악하기가 수월하며, 최근 Google은 Service mesh를 활용하여 SLO 등의 지표로 시스템을 관리하기도 한다. 하지만 도구에 의존적인 학습은 사용법을 익히는 것이 본질적인 것으로 와전될 수 있으므로 우선은 통상적으로 중점을 두는 주제들을 기준으로 학습하고자 한다.

우선 포스팅 목표는 아래와 같이 잡아보았다.
1) MySQL 기본 지식 + 쿼리 동작방식 + MySQL Server 튜닝
2) 장애시 응급처치 방법 및 성능 개선 대상 식별
3) 인덱싱 + 실행계획
4) SQL 성능 개선
5) 캐시와 배치 처리
6) 트랜잭션
7) 백업 및 복구 전략
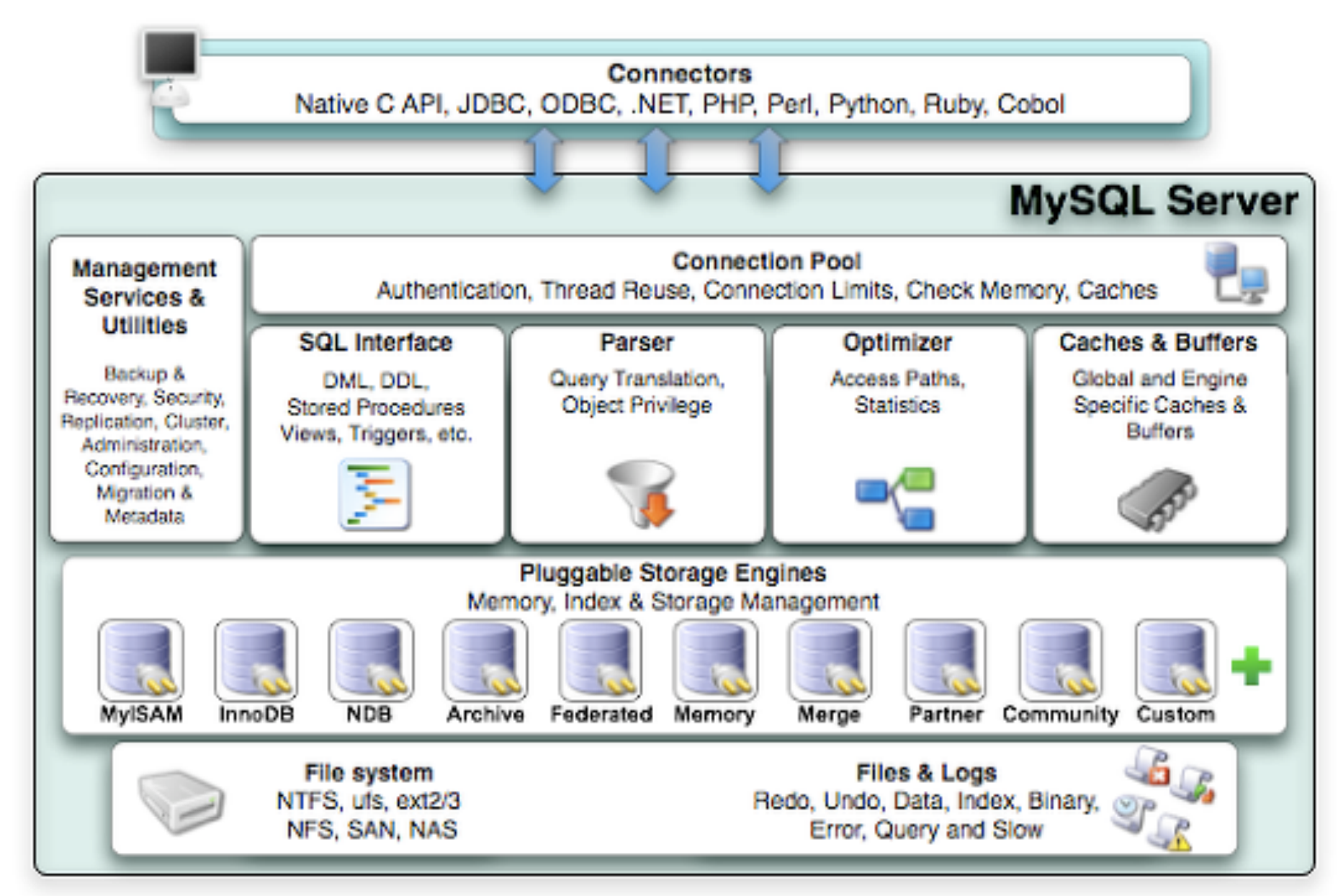
3. MySQL 기본 지식
MySQL Server와 관련하여 기본적으로 알아두면 좋을 내용 (Nested Loop Join, Storage Engine, Replication)등에 대해서 링크에서 간략히 잘 설명하고 있다.
우선, 각 영역에서 최적화와 관련해서 어떤 주제들이 있을까?

1) Client
- 복수 건의 레코드를 한번의 호출로 집합 처리하거나, 두 개 이상의 쿼리를 한 쿼리로 통합 처리함으로써 호출 수를 줄임
- JDBC Statement를 캐싱 (쿼리 문장 분석, 컴파일, 실행의 단계를 캐싱, PreparedStatement는 처음 한 번만 세 단계를 거친 후 캐시에 담아서 재사용)
- DB Connection Pool을 사용하여 객체를 생성하는 부분에서 발생하는 대기시간을 줄이고 네트워크 부담을 줄임

2) Database Engine
- 파일시스템에 저장된 데이터가 조회되면 해당 데이터를 메모리 데이터 캐시에 저장해 이후 동일 데이터 조회 시 파일시스템의 물리적인 입출력이 발생하지 않게 함.
- Server Tuning

3) Filesystem
- SSD 사용
- SQL을 최적화하여 필요이상의 데이터 블록 읽기 방지. SQL 튜닝이란, 읽는 블록 수를 줄여주는 것을 의미

4. 쿼리 동작 방식
0) Query Caching : SQL문이 Key, 쿼리의 실행결과가 Value인 Map이다. 다음의 확인절차를 거쳐 쿼리 캐시의 결과를 반환한다.
- 요청된 쿼리 문장이 쿼리 캐시에 존자하는가?
- 해당 사용자가 그 결과를 볼 수 있는 권한이 있는가?
- 트랜잭션 내에서 실행된 쿼리인 경우 가시 범위 내에 있는 결과인가?
- 호출 시점에 따라 결과가 달라지는 요소(RAND, CURRENT_DATE 등)가 있는가?
- 캐시가 만들어지고 난 이후 해당 데이터가 다른 사용자에 의해 변경되지 않았는가?
- 쿼리에 의해 만들어진 결과가 캐시하기에 너무 크지 않은가?
1) Parsing : 사용자로부터 요청된 SQL을 잘게 쪼개서 서버가 이해할 수 있는 수준으로 분리한다.
2) Preprocessor : 해당 쿼리가 문법적으로 틀리지 않은지 확인하여 부정확하다면 여기서 처리를 중단한다.
(일괄처리(batch) 내에 있다면 일괄처리 전체를 중단한다.)
3) Optimization : 실행계획(Exception Plan)이란, 이 단계에서의 출력을 의미한다.
- 쿼리 분석: Where 절의 검색 조건인지 Join 조건인지 판다
- 인덱스 선택: 각 테이블에 사용된 조건과 인덱스 통계 정보를 이용해 사용할 인덱스를 결정
- 조인 처리: 여러 테이블의 조인이 있는 경우 어떤 순서로 테이블을 읽을지 결정
4) Handler (Storage Engine): MySQL 실행엔진의 요청에 따라 데이터를 디스크로 저장하고 디스크로부터 읽어오는 역할을 담당한다. MySQL 엔진에서는 스토리지 엔진으로부터 받은 레코드를 조인하거나 정렬하는 작업을 수행한다.
일반적으로 쿼리는 아래와 같은 순서로 수행된다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
5) SELECT
1) FROM
2) WHERE
3) GROUP BY
4) HAVING
6) ORDER BY
1) 해당 데이터가 있는 곳을 찾아가서
2) 조건에 맞는 데이터만 가져와서
3) 원하는 데이터로 가공
4) 가공한 데이터에서 조건에 맞는 것만
5) 선택해서
6) 정렬
|
- 실행계획과 관련해 보다 자세한 설명을 원한다면 이 링크를 참조하길 바란다.
5. SQL에 정답은 없다.
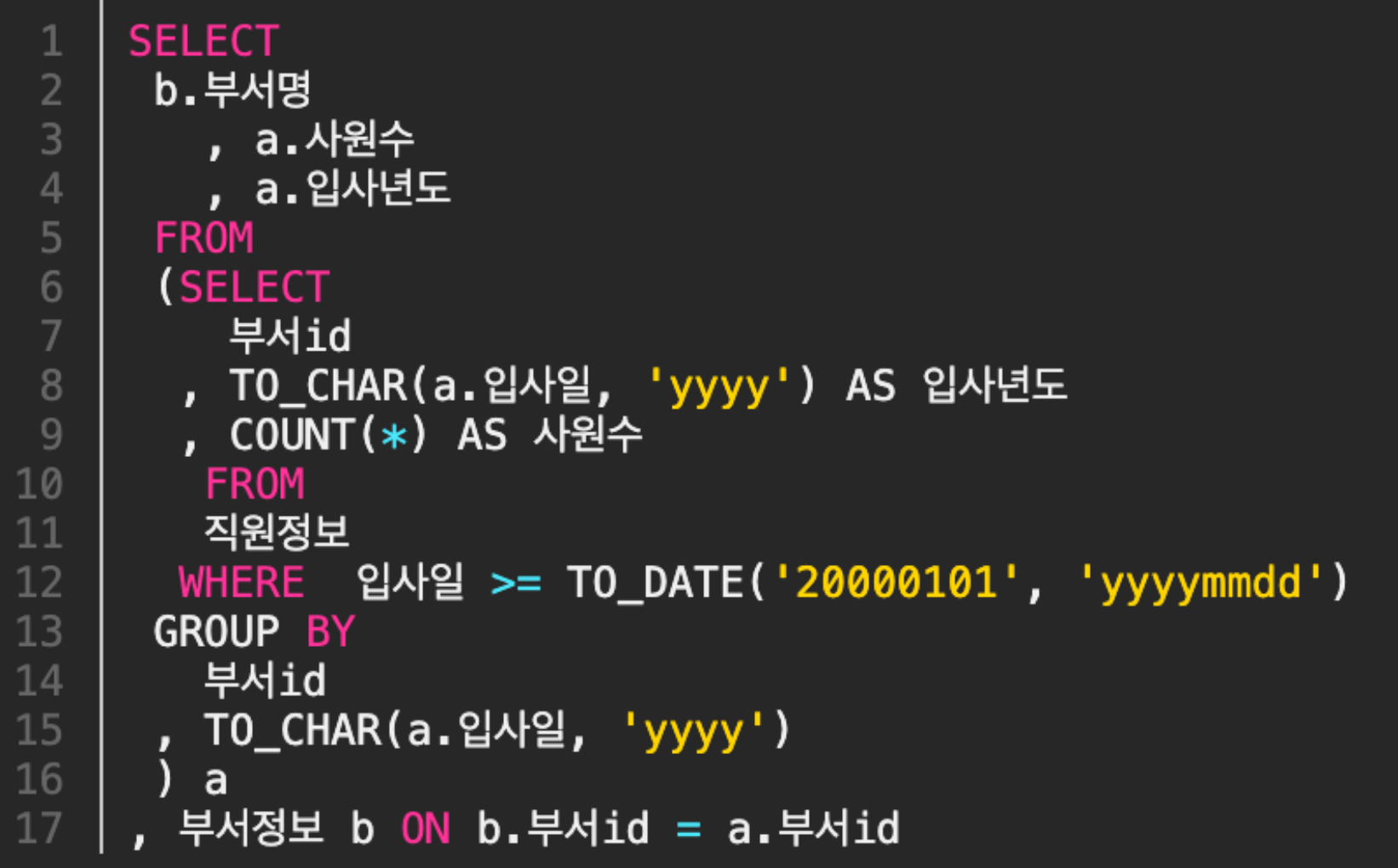
우선 아래의 쿼리를 봐보자

언뜻보면, 위의 쿼리로도 괜찮다고 생각할 수 있지만, 아래와 같이 개선할 수 있다.
1) Column을 가공하지 말자
TO_CHAR(입사일) >= '2000'보다 입사일 >= TO_DATE(yyyymmdd)가 낫다.
보통 처음에 Index 생성시 Column 이름을 쓰기 때문에, Column을 가공하면 Index를 안탄다.
2) 범위를 줄이자
부서ID를 기준으로 GROUP BY를 먼저 하고 WHERE 조건을 넣을 경우 직원정보테이블과 부서정보테이블이 1:1관계가 된다.
3) 불필요한 함수 사용 자제
SUBSTR(TO_CHAR(...)) -> TO_DATE(...)
그럼 이제 아래의 쿼리를 봐보자
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
SELECT A.계좌번호, B.고객번호, B.고객명, C.적립금,
(SELECT 이름
FROM 사원 A
WHERE D.사원번호 = A.사원번호) 담당자_이름 -- 스칼라 서브쿼리
FROM 계좌 A,
(SELECT 고객번호, MAX(적립금) 적립금
FROM 포인트
WHERE 적립일 = '20180324') C -- 인라인뷰 서브쿼리
WHERE NOT EXISTS
(SELECT 'X'
FROM 입금_목록 B
WHERE A.계좌번호 = B.계좌번호
AND B.거래일자 LIKE '201803%') -- 서브쿼리
AND A.지점_위치 = '서울'
AND A.고객번호 = C.고객번호;
|
1) 스칼라 서브쿼리 : Select 절에 추가로 쿼리를 사용하는 것, 하나의 레코드만 리턴이 가능하며, 두개 이상의 레코드는 리턴할 수 없다.
2) 인라인뷰 서브쿼리 : From 절에서 테이블들이 있는 위치 괄호 안에 작성하는 것
3) 서브쿼리 : Where절에 추가로 쿼리를 사용하는 것
이처럼 서브쿼리도 종류가 다양한데, 과연 Join과 Sub-Query를 작성하면서 무엇을 주의해야할까?
|
1
2
3
4
5
6
7
|
SELECT StyleNM
FROM Styles
WHERE CountryFK IN (
SELECT CountryID
FROM Countries
WHERE CountryNM = 'Belgium'
);
|
- Filter는 항상 Main SQL이 먼저 수행되며, 서브쿼리는 Main SQL에서 추출된 데이터의 값을 전달받아 매번 확인하는 형태로 수행된다. 즉, Main SQL에서 추출된 데이터 건수만큼 서브쿼리가 반복적으로 수행되며 처리되는 방식이다.
즉, 위의 쿼리는 IN 절 조건에서 서브쿼리가 반환한 값과 Styles 테이블에서 값이 동일한 Row를 찾으려면 서브쿼리가 먼저 실행되어야 한다. 서브쿼리에 있는 테이블의 크기가 크다면 비효율적이다. 또한 만약, WHERE 절에 서브쿼리가 많을 경우 Optimizer가 SQL에 대한 최적의 실행계획을 수립하는 것이 힘들다. 왜냐하면 서브쿼리들이 가질 수 있는 모든 조합에 대한 Cost를 계산해야 하므로 Optimizer가 실행계획을 최적화하는 과정이 더 부하가 될 수 있기 때문이다.
|
1
2
3
4
5
|
SELECT s.StyleNM
FROM Styles AS s
INNER JOIN Countries AS c
ON s.CountryFK = c.CountryID
WHERE c.CountryNM = 'Belgium';
|
- Belgium이라는 국가 이름이 여러 개가 있는 등 중복된 값이 있는 경우 원치 않은 결과가 반환될 수도 있다.
|
1
2
3
4
5
6
7
|
SELECT s.StyleNM
FROM Styles AS s
WHERE EXISTS (
SELECT NULL
FROM Countries
WHERE CountryNM = 'Belgium'
ANS Countries.CountryID = s.CountryFK
|
- EXISTS 연산자의 경우 서브쿼리 전체를 처리하지 않고 단순히 명시된 관계정보만 확인해서 true 혹은 false를 반환한다.
6. MySQL Server Tuning
MySQL 서버에 요구되는 것은, '데이터를 얼마나 빨리 내보내고 저장할 수 있는가' 이다. 이에 맞춰 Server 튜닝, 테이블 설계 및 SQL 최적화 등의 접근 방법이 있다. 그 중 MySQL Server 튜닝은 MySQL의 데이터베이스 시스템 관련 파라미터들에 대한 튜닝과 각각의 스토리지 엔진 관련 튜닝으로 나뉘는데, 여기서는 시스템 관련 파라미터들에 대한 튜닝을 주로 다루려 한다. 이는 my.cnf 파일을 수정하여 MySQL 커넥션에 관한 부분과 메모리에 관한 부분을 제어한다.
사실, my.cnf의 파라미터 튜닝 등의 세세한 튜닝보다도 우선 슬로우쿼리의 대다수는 I/O를 다수 발생시키고 있기 때문에 슬로우 쿼리를 파악하고 개선해야 한다. - https://jsonobject.tistory.com/408
1) MySQL 메모리 튜닝
(1) 쓰레드 관련 메모리 튜닝
MySQL은 커넥션마다 하나의 쓰레드를 생성시켜 요청을 처리하게 된다. 그래서 쓰레드가 생성되는 시점에 쓰레드에 메모리가 할당되며 많은 쓰레드가 생성되고 사라지면서 과부하가 발생한다.
mysql> SHOW STATUS LIKE ‘%THREAD%’;
Threads_connected가 Threads_ cached에 비해 매우 높다면 thread_cache_size를 높여줄 필요가 있다. Thread_cache_size는 지나치게 높여둘 필요는 없으며 일반적으로 threads_connected의 피크 치보다 약간 낮은 수치 정도를 설정하는 것이 좋다. 이를 통해 쓰레드가 생성되고 소멸되면서 겪게 되는 메모리, 각종 자원, 시간 등의 낭비를 줄일 수 있다.
(2) 캐싱 관련 메모리 튜닝
버퍼 풀(buffer pool) 크기, 키 캐시(key cache) 크기, 쿼리 캐시 크기 등과 관련된 파라미터가 있다.
- 버퍼의 종류
1) Global Buffer: mysqld에서 내부적으로 하나만 확보되는 버퍼
2) Thread Buffer: 쓰레드(커넥션)별로 확보되는 버퍼
즉, 쓰레드 버퍼에 많은 메모리를 할당하면 커넥션이 늘어났을 때 순식간에 메모리가 부족해진다.
버퍼에 할당할 메모리가 많으면 성능이 올라가지만, 서버의 기준치를 넘기면 swap이 발생하여 성능이 떨어진다.
- innodb_buffer_pool_size : InnoDB의 데이터나 인덱스를 캐시하기 위한 메모리상의 영역, 글로벌 버퍼이므로 크게 할당할 것을 권함(최대 512MB)
- innodb_log_file_size : InnoDB의 갱신로그를 기록하는 디스크상의 파일. 메모리가 아니지만 튜닝에 있어 중요함. 많이 할당할수록 성능이 향상됨(최대 128MB)
- join_buffer_size, read_buffer_size : 인덱스를 사용하지 않는 테이블 결합/스캔 시에 사용됨
- 쿼리 캐시
쿼리 캐시란 빈번하게 수행되는 Select 관련 쿼리와 쿼리의 결과를 임시 저장하는 캐시 메모리이다. 데이터베이스 시스템에서 가장 시간이 많이 걸리는 것은 바로 디스크를 액세스하는 작업이다. 그러므로 디스크를 액세스하는 작업을 줄이는 것이 가장 크게 성능을 올리는 것이다. 쿼리 캐시는 Select 쿼리에만 해당되며 쿼리 캐시를 사용하지 않게 되거나 쿼리 캐시에 저장된 내용을 초기화하게 되는 경우는 다음과 같다.
1) 데이터나 테이블 구조가 변경되었을 때
2) 쿼리 캐시에 저장된 것과 다른 쿼리가 접수되었을 때
3) 하나의 트랜잭션이 commit과 함께 마무리되었을 때
4) 쿼리가 내부적으로 임시 테이블을 생성해야 할 때
- 쿼리 캐시 최적화
일반적으로 쿼리 캐시 크기는 시스템 전체 메모리의 5%에서 10% 사이를 사용하는 것이 보통이다. 일단 이 사이의 값으로 설정한 후 모니터링을 통해 쿼리 캐시 사용률이 100%에 가깝도록 하는 것이 좋다.
다음으로 쿼리 캐시에서 받아들일 쿼리의 최대 크기를 설정하는 것이 필요하다. Query_cache_limit 옵션으로써 기본 값은 1MB이나 이는 너무 큰 값일 경우가 많다. 빈번하게 사용되는 쿼리의 용량이 어느 정도인지 살펴본 후 이보다 10% 정도 높은 값을 설정하자.
2) MySQL 커넥션 튜닝
- 커넥션에 대한 모니터링은 아래의 명령어로 가능하다.
mysql> SHOW STATUS LIKE ‘%CONNECT%’;
mysql> SHOW STATUS LIKE ‘%CLIENT%’;
- connect_timeout은 MySQL이 클라이언트로부터 접속 요청을 받는 경우 몇 초까지 기다릴지를 설정하는 변수이다. 기본 값은 5초이며 일반적으로 수정할 필요는 없다.
- Interactive_timeout은 ‘mysql>’과 같은 콘솔이나 터미널 상에서의 클라이언트 접속을 말한다. 기본 값으로 8시간이 잡혀 있으나 1시간 정도로 낮추는 것이 좋다.
- wait_timeout은 접속한 후 쿼리가 들어올 때까지 기다리는 시간이다. 접속이 많은 데이터베이스 시스템에서는 이 값을 낮춰 sleep 상태로 커넥션만 유지하고 있는 클라이언트들의 접속을 빠르게 끊어줘 동시 접속을 낮추는 것으로 전체 성능을 크게 향상시킬 수 있다.
하지만 주의할 점은 너무 낮추게 되면 실제로 서비스를 하기도 전에 끊어진다든지 지나치게 잦은 커넥션이 발생한다는 것이다. 일반적으로 15~20 사이의 값이 적당하며 SHOW STATUS를 통해 aborted_client가 가장 적게 발생하도록 값을 맞춰야 한다. Aborted client는 2% 아래인 것이 바람직하며 물론 없는 것이 가장 좋은 상태이다.
- net_buffer_length/max_allowed_packet
MySQL의 커넥션은 쓰레드 단위로 일어나는데 각 쓰레드가 생성되면서 메시지 전송을 위한 버퍼를 생성하게 된다. 일반적으로 max_allowed_packet만을 정해 놓는 경우가 많은데 net_buffer_ length를 설정해 두면 그 용량을 넘는 메시지를 전달해야 할 경우 자동으로 이 값을 늘리게 된다. 그러므로 가장 효율을 높이기 위해서는 net_buffer_length를 일반적인 쿼리에서 전송되는 바이트 값의 평균 정도를 생각하여 충분히 낮은 값을 설정해두고 max_allowed_ packet은 최대로 전송될 수 있는 높은 값을 설정하는 것이 좋다. max_allowed_packet은 1GB까지 설정할 수 있다.
- max_connections/back_log
max_connections는 서버가 허용하는 최대한의 커넥션 수이다. MySQL 데이터베이스를 운영하고 있는 서버의 사양에 따라 달라질 수 있으며 일반적으로 120~250개 정도로 설정하는 것이 보통이다. 하지만 접속이 많고 고용량 서버의 경우 1000개 정도의 높은 값을 설정하는 것도 가능하다. Too many connection 에러가 발생하지 않도록 적절한 값을 설정하는 것이 중요하다. Back_log의 경우 max_connection 이상의 접속이 발생할 때 얼마만큼의 커넥션을 큐에 보관할지에 대한 설정 값이다. 기본 값은 50이며 접속이 많은 서버의 경우 이 값을 늘릴 필요가 있다.
- skip-name-resolve
외부로부터 접속 요청을 받을 경우 인증을 위해 IP를 호스트네임으로 바꾸는 과정이 수행된다. 말하자면 hostname lookup 과정이 수행되는데 접속이 많은 서버에서는 이 과정에서 상당히 많은 과부하가 발생한다. 그러므로 인증 부분을 호스트 기반이 아닌 IP 기반으로 변경하고 이 같은 옵션을 통해 hostname lookup 과정을 생략하면 눈에 띄는 성능 향상을 경험할 수 있을 것이다.
'Infra Structure > .system' 카테고리의 다른 글
| Kubernetes Networking #1 (0) | 2020.03.15 |
|---|---|
| 200 vs 404 (0) | 2020.02.12 |
| HTTP 완벽가이드 스터디 #8 Gateway, Tunnel (0) | 2019.10.12 |
| HTTP 완벽가이드 스터디 #7 Cache (0) | 2019.10.05 |
| HTTP 완벽가이드 스터디 #6 Proxy Server (0) | 2019.09.23 |